Recently I have been exploring the COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University. This data set is interesting for many reasons and I plan on using it in many examples here.
Challenge
The most accurate files in this repository are the time series files. These files have several descriptive columns (Country, Province, Latitude, Longitude) and then a column for each day starting at 2020-01-22 with the count of cases (confirmed, recovered, or deaths depending on the file) for that date. While this layout makes basic analysis easy, it is not good for ad hoc analysis in a tool like Power BI.
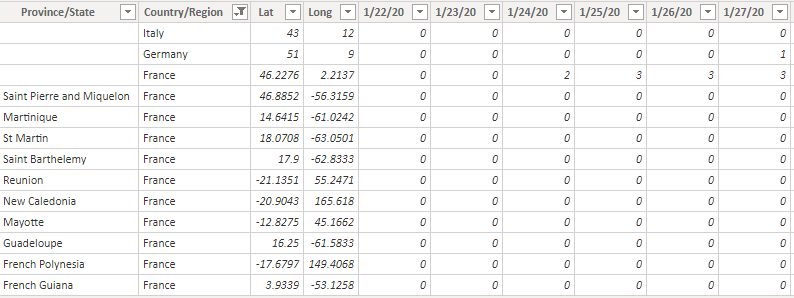
Additionally, this layout causes problems when importing the file using SQL Server Integration Services. SSIS expects the structure of the file to remain the same with each execution and these files change every day.
Loading the Data
For this reason, I decided to load the descriptive columns as they are, but all of the value columns will be loaded into a single column which has the values as an array of comma separated values. Because I am most comfortable using T-SQL, I planned to split this column and unpivot it later.
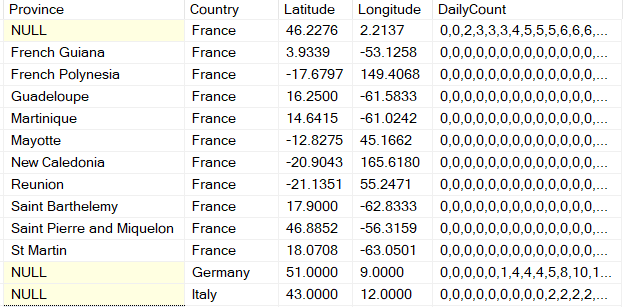
False Hope
My first thought was to use the STRING_SPLIT function which was introduced in SQL 2016, but I quickly realized this function is missing a vital piece of information.
|
|
 The
The STRING_SPLIT function does not return any information about the position in the array that was split that this row represents. While the order of the rows appears to match, there is no guarantee that it does.
JSON??
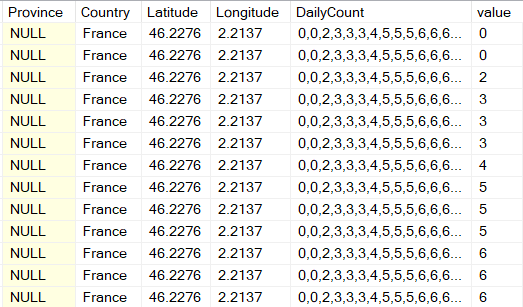
SQL Server 2016 also brought us the ability to parse JSON in SQL Server. That’s great, but how does it help? The OPENJSON function returns three fields from a JSON string: a Key, the Value, and the Type. The type is not important in this case, but the Key is… THE KEY!
a. Key. An nvarchar(4000) value that contains the name of the specified property or the index of the element in the specified array.
I can hear you now, “That’s great and all, but that field is not JSON!” Which is entirely correct, however, we can convert it into JSON easily. I wrote this table-valued function to convert a delimited list into a JSON string.
|
|
I wrote the function to take a delimited list with any single character as the delimiter and convert that list into a JSON string with a single array of ‘Elements’. Note that this function is intended for a very narrow use, namely, that of converting an array of numbers into a JSON array of numbers. Also, I made this a function because there are multiple files that will need this same operation and reusing code makes life easier!
Now that I have a JSON field I can use the OPENJSON function to return the key and the value.
|
|
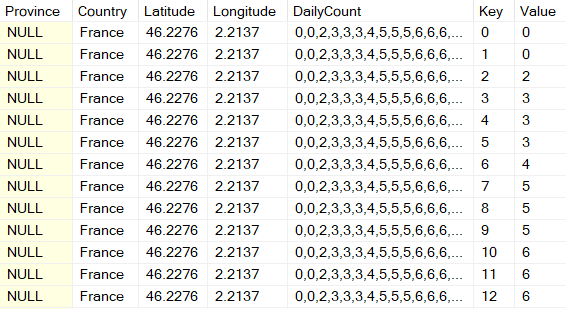 Now all I need to do is convert the key column into a date. Because these time series files all start at 2020-01-22 the logic is very easy.
Now all I need to do is convert the key column into a date. Because these time series files all start at 2020-01-22 the logic is very easy.
|
|
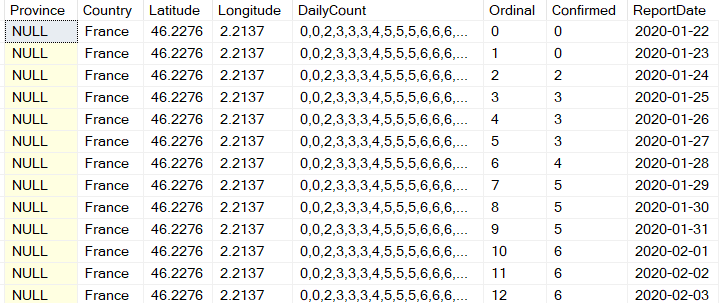
There we go, nicely unpivoted data and I did not have to use the UNPIVOT operator! I can never remember the syntax and you have to know all the column names in advance, so it wouldn’t work in this scenario either way.
This would have been much easier if STRING_SPLIT had more functionality. Aaron Bertrand [blog|twitter] wrote an excellent article about it that I highly encourage you to read and also give feedback to Microsoft on this issue here.